Pars complex documents and validate them using advanced AI all locally — your data never leaves your infrastructure
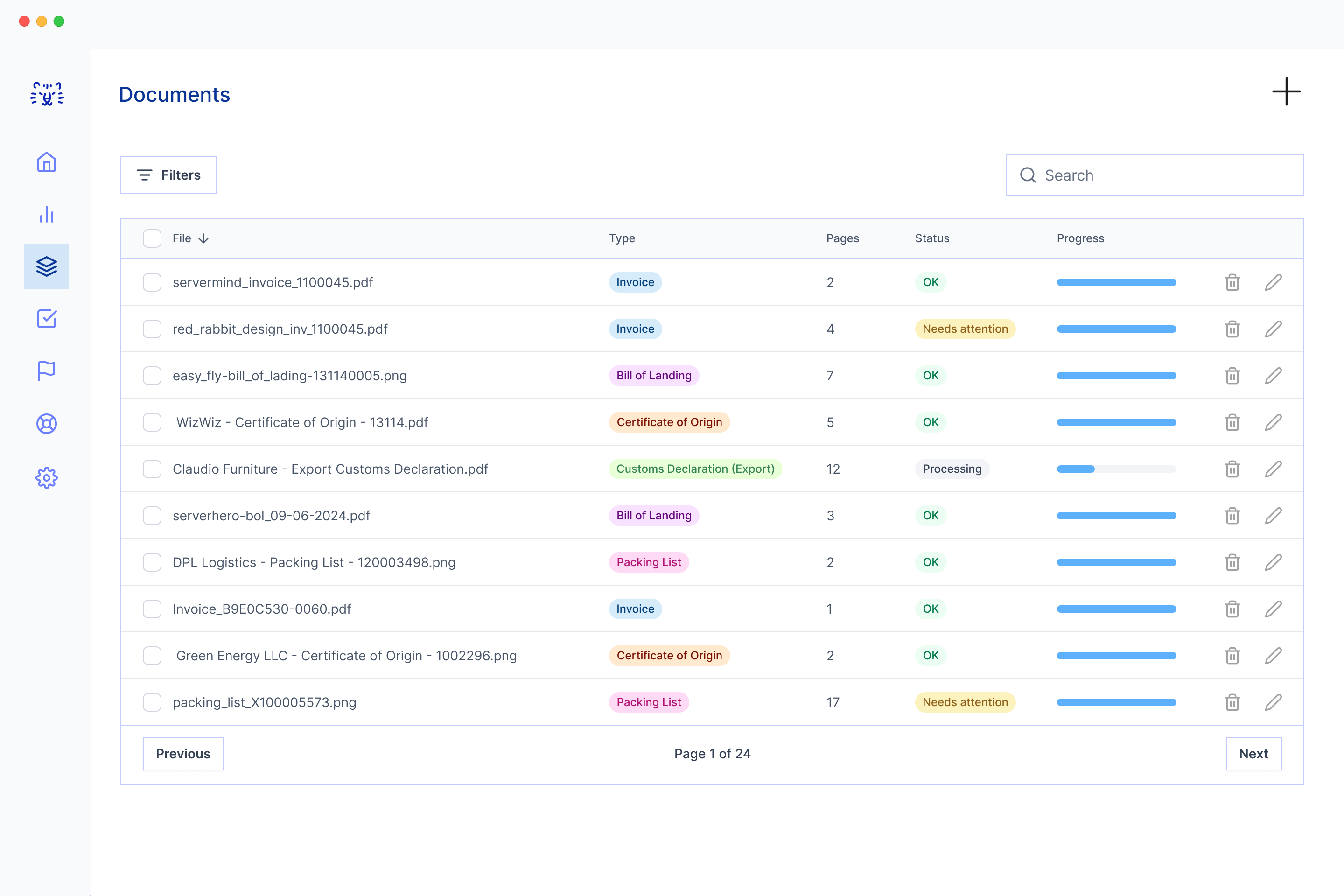
With Tygra, turn unstructured documents into data with unmatched accuracy & reliability using advanced AI that runs entirely on your infrastructure



Choose Tygra if privacy is non-negotiable for you

Fraud Detection & Prevention, KYC, Loan Application Forms, Mortgage Application Forms, Bank Statements, Invoices

Delivery Receipts, Freight Quotes, Purchase Orders, Customs Declarations, Dangerous Goods Declarations, Bills of Lading (BOL)

Risk Assessments, Policy Management, Renewal Notices, First Notices of Loss (FNOL), Insurance Claim Forms

Electronic Health Records (EHR), Medical Billing, Lab Reports, Insurance Claims, Prescription Forms

Contract Analysis, Legal Cases, Prescription Forms, Insurance Claims, Clinical Notes

Student Enrollment Forms, Transcripts, Assignment Submissions, Scholarship Applications, Attendance Records
Everything you need to know about Tygra
Tygra is a privacy-first AI document processing tool that helps you parse and validate documents automatically all locally, meaning your data never leaves your infrastructure. Tygra supports PDF, JPG, and PNG file formats.
Tygra is designed for organizations with strict privacy and compliance needs. Unlike cloud-based AI document processing tools, Tygra processes data locally on your infrastructure for absolute data sovereignty.
Tygra uses the latest open-source models, prioritizing privacy and secure data handling.
Tygra significantly outperforms traditional OCR by using advanced AI models that understand context, structure, and meaning. While OCR simply recognizes text, Tygra understands document layouts, extracts complex data relationships, and validates information according to business rules and regulations.
The deployment of Tygra requires dedicated infrastructure and IT resources but provides maximum control.

